前面学习了OpenCV基础,下面对Dlib进行快速入门,同样的进行实际例子配合学习。
Dlib简介
Dlib 是目前业内高度认可的一个包含机器学习算法的C++开源工具包,提供C++与Python接口。其人脸识别领域的相关模型工具完善。
在识别精确度上,Dlib >= OpenCV,Dlib更多的人脸识别模型,可以检测脸部68甚至更多的特征点。
在使用Dlib之前需要安装cmake。以PyCharm为例,在当前的虚拟环境中安装cmake,再安装dlib。
壹:Dlib人脸检测
一、HOG特征描述方法
1. Harr级联人脸检测与Dlib人脸检测器
前面使用OpenCV中的Harr级联人脸检测,它算是人脸识别中早期的检测方法,现在Dlib库在业内开始流行。因为很大程度上是其使用的HOG-SVM人脸检测比OpenCV Harr级联人脸检测效果更好。当然,现在两个库中也都集成了基于深度学习方法的人脸检测算法。在此我们暂时先讨论两种传统算法:
(1) OpenCV中Harr级联人脸检测优缺点
- 优点
- 几乎可以在
CPU上实时工作; - 架构简单;
- 可以检测不同比例的人脸。
- 几乎可以在
- 缺点
- 会出现大量的把非人脸预测为人脸的情况;
- 不适用于非正面人脸图像;
- 不抗遮挡。
(2) Dlib中HOG-SVM人脸检测级优缺点
- 优点
CPU上最快的方法;- 适用于正面和略微非正面的人脸;
- 模型很小;
- 在小的遮挡下仍可工作。
- 缺点
- 不能检测小脸,因为它训练数据的最小人脸尺寸为
80×80,但是用户可以用较小尺寸的人脸数据自己训练检测器; - 边界框通常排除前额的一部分甚至下巴的一部分;
- 在严重遮挡下不能很好地工作;
- 不适用于侧面和极端非正面,如俯视或仰视。
- 不能检测小脸,因为它训练数据的最小人脸尺寸为
2. HOG定义
方向梯度直方图(Histogram of Oriented Gradient, HOG)是一种在计算机视觉和图像处理中用来进行物体检测的特征描述方法。所谓特征描述方法,就是通过从图像中提取有用信息和丢弃无关信息来简化图像,并将信息运用于算法。
特征描述方法从图像中提取有用信息,那么在HOG中提取了图像哪些有用信息呢?
其实,在图像中,物体的边缘和角落包含了关于物体形状的更多信息。也就是我们平时能看到的物体轮廓。如果能够提取出图像边缘和角落的信息,将非常有利于物体检测。
而对于图像,边缘和角落周围的梯度这个特征,变化幅度很大,所以在HOG特征描述方法中,使用梯度方向的分布(直方图)作为它的特征。
3. HOG算法的基本流程
HOG算法的基本流程的基本流程,分为以下4步:
- 计算图像梯度;
- 计算
Cell中的梯度直方图; Block归一化;- 计算
HOG特征。
(1) 计算图像梯度
图像梯度是什么?
图像是由一个个像素点组成的,可以将图像看成二维离散函数
f(x,y),图像函数f(x,y)在点(x,y)的梯度G(x,y)是一个具有大小和方向的矢量,设为Gx和Gy, 分别表示水平(x)方向和垂直(y)方向的梯度。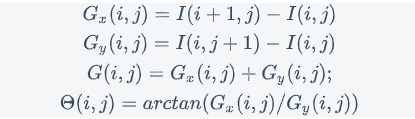
其中
I(i,j)表示(i,j)像素点处的图像的像素值,Θ(i,j)表示(i,j)像素点梯度的方向。使用OpenCV计算图像的梯度
在
OpenCV中,可以使用以下的代码快速的计算得到图像的梯度:1
2
3
4
5
6
7
8
9
10
11import cv2
import numpy as np
img = cv2.imread("./image/girl.jpg")
img = np.float32(img) / 255.0
#计算图像所有像素点的水平梯度,保存在sobelx中。1,0参数表示在x方向求一阶导数
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0, ksize=1)
#计算图像所有像素点的垂直梯度,保存在sobely中。0,1参数表示在y方向求一阶导数
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1, ksize=1)
#进而求得所有图像的梯度以及梯度角度
#其中magnitude表示梯度,angle表示magnitude对应的梯度的角度
magnitude, angle = cv2.cartToPolar(gx, gy, angleInDegrees=True)通过
cv2.imshow,效果如下图所示:
(2) 计算Cell中的梯度直方图
分析每一个像素的梯度太过细节化了,如果能从更高的角度上观察图像片更能观察出图像的一些规律,而Cell就是在像素的更高的角度。
在OpenCV中一个Cell默认是8x8个像素,所以一个Cell中其实包含了8x8 = 64个梯度与梯度角度对,这些对最终都会映射到9-bins直方图,而9-bins直方图就是横坐标有9个点的直方图。
首先得说明的是,梯度的角度是介于0和180度之间,而不是0到360度,也就是说将某个角度以及它的负数由相同的数字表示。而在这个直方图中,横坐标上的点分别是 0, 20, 40 … 180,这些值的含义与梯度的角度是一样的。
上面说到梯度与梯度角度对最终都会映射到直方图中,那如何映射呢?举个简单的例子吧,现在有一个(5,55)对,首先梯度角度为55度,它位于[40度,60度]之间,那么它会映射到第3个bins,第3个bins的值会加上他的梯度,也就是加上5。如下图所示:
也就是说,梯度角度决定了映射的bins,梯度决定了映射的值。这样就可以求出每个cell的梯度直方图了。
(3) Block归一化
梯度对于图像的光照亮度是十分敏感的,一般需要对梯度做归一化处理以亮度变化的影响。
在HOG采取的方法是:把Cell组合成大的、空间上连通的区块(Blocks)。在OpenCV中,默认的Block的大小为16x16个像素点,也就是2x2个Cell。如下图所示:
举个例子,假设有一个向量v1,它的值为[128,64,32]。经过计算可得,该向量长度是:
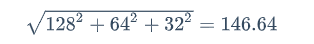
将该向量的每个元素除以146.64,得到归一化向量,[0.87,0.43,0.22]。同样的,如果将v1x2,能得到新向量v2[256,128,64],对其归一化的结果仍然为[0.87,0.43,0.22],也就是说归一化会去除对数值大小的影响。
如果对Block归一化处理,当光照强度变化大时,该区域的梯度值普遍会更大,从而减少了光照的影响。虽然可以以Cell为单位,对图片进行归一化处理,但更好的是在比Cell更大尺寸的Block上进行归一化。因为Block的像素点更多,受到光照的影响会更小。在一个16×16块中有将包含4个Cell,那么一个块中就可以连接形成一个长度为4x9=36的向量(1个Cell中包含9个Bins)。
(4) 计算HOG特征
将所有的block归一化后得到的向量合起来就形成了一个HOG特征。为了计算一张图片的所有HOG特征,需要计算所有的Block。通过移动Block窗口的方式进行一一计算,其过程如下图所示:
4. 使用OpenCV计算HOG特征
上面详细的讲解了Hog特征描述方法的原理。现在我们可以借助OpenCV中封装好的方法来计算HOG特征。
1 | # 1.使用cv2.HOGDescriptor()函数声明HOG特征描述方法 |
二、训练人脸检测模型
训练一个人脸检测器的流程一般如下:
- 准备数据;
- 训练人脸检测模型;
- 验证模型效果。
1. 准备数据
(1) 训练集
使用4张图片作为训练集数据,其中人脸相关的标注数据,存放于XML文件中,格式如下:
1 |
|
其中,image file 代表图像文件名。
box中top、left、width和height指定了人脸区域,一张图中可能包含多个人脸,所以可能有多个box。
(2) 测试集
使用5张图片作为测试集数据。同样的,其中人脸相关的标注数据,存放于XML文件中。其格式与训练集文件格式相同。
2. 训练模型
在准备好训练集和测试集之后,便开始训练人脸检测模型了。大量的研究和实验表明,在物体检测的领域中,与HOG一起使用的算法中,SVM算法的效果是最好的。由于人脸检测也是物体检测的一种,所以我们也会的训练模型也会基于HOG+SVM。
(1) 训练主要流程
一个完整的训练流程大致如下:
- 设置
SVM的参数; - 读取用于训练的
xml文件training.xml; - 获取用于训练集中图片的人脸区域;
- 将人脸区域转为
HOG特征; - 将生成的
HOG特征作为SVM的输入; SVM训练数据生成模型。
(2) 使用Dlib训练模型
使用Dlib提供的训练函数来训练的模型,主要分为如下几步:
定义模型训练需要的参数
人脸检测模型中包含大量可以设置的参数,所以我们首先定义参数设置函数:
1
options = dlib.simple_object_detector_training_options()
大部分参数,在此使用默认值,针对我们的训练集,主要设定如下几个参数:
C:SVM的参数。在SVM中,C是惩罚系数,即对误差的宽容度。C越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差。1
2
3
4
5
6
7
8
9
10
11# 在本例中将C的值设置为5
options.C = 5
# add_left_right_image_flips:对用于训练的图片做镜像处理,从而将训练集扩大一倍。一般都会设置为True。
options.add_left_right_image_flips = True
# be_verbose,是否输出训练的过程中的相关信息。我们设置为True:
options.be_verbose = True
# num_threads,设置训练时使用的cpu的核数。在这里我们设置为4:
options.num_threads = 4
调用训练函数,生成训练完成的模型
参数设定完成,就可以使用
dlib.train_simple_object_detector()进行训练了。改训练函数封装了前面提到的第2到6步训练流程,示例如下:1
dlib.train_simple_object_detector(training_xml_path, "detector.svm", options)
其中,
training_xml_path是训练数据标记文件路径,options是我们前一步设置的值,将最后的检测器输出为detector.svm文件。
完整的训练示例:
1 | import dlib |
运行训练程序,输出如下:
1 | objective: 1.79764 |
3. 检验模型的效果
在训练完成之后,我们可以加载我们训练好的模型并在测试集上测试我们的模型结果,示例代码如下:
1 | testing_xml_path = os.path.join(faces_folder, "testing.xml") |
运行测试程序,输出如下:
1 | Training accu\fracy: precision: 1, recall: 1, average precision: 1 |
实际的刚训练完成的模型效果,模型的效果还不错:
三、检测并绘制人脸区域
1. 加载模型
前面我们训练了自己的模型,并把模型保存在了detector.svm中。如果想要在加载自己训练的基于HOG-SVM的模型,那么我们可以调用dlib.simple_object_detector()方法:
1 | # 函数声明 |
前面我们自己训练的人脸模型由于训练数据的很少,所以实际应用的效果会不太好。在Dlib中,已经有通过大量的数据和参数优化训练的效果非常的模型,该模型也是基于HOG+SVM的。所以在此我们使用Dlib中训练好的模型。加载该模型的代码如下:
1 | detector = dlib.get_frontal_face_detector() |
2. 使用模型检测人脸区域
在加载了模型之后,可以通过detector()来检测图片中的人脸区域:
1 | dets= detector(img, 1) |
其中,
- 第一个参数
img为图片对象; - 第二个参数为
上采样的值(上采样实际上也就是将一个尺寸较小的图像通过算法使之变为尺寸较大的图像,这里我们将它的值设为1,能会帮助我们检测到更多的人脸)。 - 返回的
dets表示模型检测到的img中的所有人脸区域。
因为一张图片中可能有多张人脸,也就意味着可能会有多个人脸区域了,所以dets是一个数组。 对于dets中的每一个元素d,都可以通过d.left(),d.top(), d.right(), d.bottom()分别获取到d对应的人脸区域的最左,最上,最右和最下的四个值。
完整代码如下:
1 | import cv2 |
3. 绘制人脸区域
(1)使用OpenCV绘制矩形区域
废话不说,直接看代码:
1 | import cv2 |
(2)使用Dlib绘制人脸区域
Dlib中也提供了绘制人脸区域的方法,主要分为3步:
使用
image_window()新建图像窗口:1
win = dlib.image_window()
指定窗口图片:
1
2win.clear_overlay()
win.set_image(img)绘制人脸区域
1
win.add_overlay(dets)
Dlib默认绘制方法非常简洁,完整的代码示例如下:
1 | import cv2 |
结果的效果同上。
贰:Dlib人脸特征提取
一、检测人脸特征点
1. 人脸特征点含义
在检测到人脸区域之后,接下来要研究的问题是获取到不同的脸部的特征,以区分不同人脸,即人脸特征检测(facial feature detection)。它也被称为人脸特征点检测(facial landmark detection)。
人脸特征点通常会标识出脸部的下列数个区域:
- 右眼眉毛(
Right eyebrow); - 左眼眉毛(
Left eyebrow); - 右眼(
Right eye); - 左眼(
Left eye); - 嘴巴(
Mouth); - 鼻子(
Nose); - 下巴(
Jaw)。
2. 人脸特征点检测原理
检测人脸特征点,分为如下两步:
第一步:定位图像中人脸区域;
第二步:在人脸区域内检测出人脸关键特征;
其中,第一步可以使用OpenCV中Harr检测器或者Dlib中HOG加SVM的检测器。
Dlib中使用的人脸特征检测,原理来自2014年,由Vahid Kazemi和 Josephine Sullivan在论文 《One Millisecond Face Alignment with an Ensemble of Regression Trees》中提出的人脸特征点评估的方法。
论文中方法的主要思想是:使用级联回归树(ensemble of regression trees, ERT),即使用级联回归因子,基于梯度提高学习的回归树方法。首先需要使用一系列标定好的人脸图片作为训练集,然后会生成一个模型。使机器学习模型能够找出任何脸上的这些特征点。
简要的分为以下三步:
- 定义一张脸上的
68个具体的特征点(landmarks); - 标记面部特征点,获得带标记的训练数据。需要手动标记图像上的面部特征点,标签指定围绕每个面部结构的区域;
- 给定训练数据,训练回归树的集合,直接从像素强度本身估计面部界标位置,得到模型。
3. Dlib人脸特征点模型
Dlib提供两种人脸检测模型:
shape_predictor_5_face_landmarks.dat: 检测5个人脸特征点,指的是双眼的眼头及眼尾以及鼻头这五个位置。因为只检测五个点,所以执行速度很快。如下图所示:shape_predictor_68_face_landmarks.dat:检测68个人脸特征点。如下图所示:
4. 使用Dlib检测人脸特征点
利用Dlib的正向人脸检测器 get_frontal_face_detector(),进行人脸检测,提取人脸外部矩形框 :
1 | detector = dlib.get_frontal_face_detector() |
返回的faces为识别出的脸部数组。利用训练好的人脸68点特征检测器,进行人脸面部轮廓特征提取:
1 | predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") |
示例如下:
1 | import cv2 |
程序执行效果如下:
1 | 人脸数: 1 |
二、绘制人脸特征点
1. 使用Dlib绘制人脸特征点
Dlib本身提供了绘制特征点的方法。主要分为三步:
使用
image_window()新建图像窗口;1
win = dlib.image_window()
指定窗口图片
1
2win.clear_overlay()
win.set_image(img)绘制面部轮廓
1
2
3
4# 使用predictor来计算面部轮廓
shape = predictor(img, faces[i])
# 绘制面部轮廓
win.add_overlay(shape)绘制人脸区域矩阵
1
2# 绘制矩阵轮廓
win.add_overlay(faces)
完整代码示例:
1 | import dlib |
效果如下:
2. 使用OpenCV绘制人脸特征点
同样,可以使用OpenCV的绘点函数,绘制出每一个点:
1 | # 函数声明 |
其中,各参数含义如下:
image: 图片对象;center: 圆心坐标;radius: 圆半径;color: 以BGR方式指定的颜色,例如(255,0,0)是蓝色;thickness:线的粗细。
完整代码示例:
1 | import cv2 |
效果如下:
对比总结:
从最后的效果图上看,Dlib是将人脸的轮廓用线条描绘了出来,而OpenCV将各个特征点描了出来,这是最直观的区别。转观代码,大同小异,注意两个地方:在Dlib中不需要将原图转换成灰度图像,而OpenCv会转换成灰度图像来提高处理速度;另一个点在于同样在for循环里,Dlib使用preditor来计算轮廓,再通过win.add_overlay()去绘制,因此才有了连续的轮廓,而OpenCV是采用shape.parts()遍历特征点的方式一个一个画“圈”,这才形成了一个又一个特征点。
三、训练人脸特征点模型
1. 数据集
前面使用的Dlib中提供的68点特征检测模型,使用的数据集来自300-W(300 Faces In-The-Wild Challenge)。300-W是一项,专注于人脸特征点的检测的竞赛,通常与ICCV这类著名的计算机视觉活动相伴举行。在该竞赛中,参赛队伍需要从600张图片中检出人脸,并且将面部的68个特征点全部标记出来。
300W数据的压缩包有2G多。包含各种各样已经标记好的人脸信息。因为在如此大的数据集上训练需要大量的资源和时间。所以,在本次实训的学习中,使用极少量的数据集来训练。
2. 训练集
我们使用4张图片作为训练集数据。其中人脸相关的标注数据,存放于XML文件中,格式如下:
1 |
|
其中:
image file代表图像文件名;box中top、left、width和height指定了人脸区域,一张图中可能包含多个人脸,所以可能有多个Box;part即为对应人脸特征点,每张图有68个标记点。
3. 测试集
使用5张图片作为测试集数据。同样的,其中人脸相关的标注数据,存放于XML文件中。其格式与训练集文件格式相同。
4. 训练模型
(1)定义模型训练需要的参数
人脸检测模型中包含大量可以设置的参数,所以首先定义参数设置函数:
1 | options = dlib.shape_predictor_training_options() |
大部分参数,在此使用默认值,针对当前的训练集,主要设定如下几个参数:
Oversampling_amount:通过对训练样本进行随机变形扩大样本数目。比如原本有N张训练图片,通过设置该参数,训练样本数将变成N * oversampling_amount张。所以一般而言,值越大越好,只是训练耗时也会越久。因为本例中训练集数据较少,所以我们将值设得较高(`300`):1
options.oversampling_amount = 300
nu:正则项,nu越大,表示对训练样本fit越好。本例中通过增加正则化(将
nu调小)和使用更小深度的树来降低模型的容量:1
2options.nu = 0.05
options.tree_depth = 2tree depth:树深。be_verbose:是否输出训练的过程中的相关训练信息。
(2)调用训练函数,生成训练完成的模型
使用dlib.train_shape_predictor进行训练,示例如下:
1 | dlib.train_shape_predictor(training_xml_path, "predictor.dat", options) |
training_xml_path是训练数据标记文件路径,options是我们前一步设置的值,将最后的检测器输出为 predictor.dat文件。
(3)调用测试模型函数,测试训练完成的模型
最后,调用test_shape_predictor进行模型测试。
1 | dlib.test_shape_predictor(testing_xml_path, "predictor.dat") |
表示,读取predictor.dat和testing_xml_path测试数据文件进行模型测试。
完整训练代码示例:
1 | import os |
运行训练程序:
1 | Training with cascade depth: 10 |
5. 使用训练完成的模型
1 | # 人脸区域检测器 |
叁:Dlib人脸识别
一、Dlib人脸检测的基本原理
1. 如何计算特征向量
在人脸特征点检测中,了解了如何获取人脸的特征点。但是特征点只是用于标识人脸关键点的坐标而已,如果想要实现人脸识别,那么必须将特征点转换为特征向量。
(1)加载人脸识别模型
首先,通过dlib.face_recognition_model_v1()加载人脸识别的模型。
1 | # 函数声明 |
Dlib提供了训练好的模型,下载地址。事先下载并解压好了文件,并将其放在step1/model/dlib_face_recognition_resnet_model_v1.dat。加载模型代码如下:
1 | import dlib |
(2)计算特征向量
在加载完模型之后,需要先使用前面学到的知识,先检测特征点。具体代码如下所示:
1 | # 读取图片 |
通过上面的代码,检测到人脸的特征点,并将它们保存在shape中。下面通过facerec.compute_face_descriptor()来计算特征向量,它的函数声明如下:
1 | facerec.compute_face_descriptor(图片对象, 特征点) |
至此,计算得出了人脸特征向量。
2. 计算欧氏距离
欧氏距离(也称欧几里得距离)是一个常用的的距离度量,它指的是在空间中两个向量(点)之间的直线距离。欧氏距离越小,说明两个向量越接近,也就是两个向量差异越小。
假设在两个向量分别为x(x1,x2,...,xm)和y(y1,y2,..,ym),则这两个向量的欧氏距离的计算公式为:
$$
\sqrt{(x_1−y_1)^2 + (x_2−y_2)^2 +..+ (x_m−y_m)^2}
$$
在Python中可以通过长度为m的列表来表示维数为m的向量。例如x为(1,2,3,4,5),那么它可以表示为x=[1,2,3,4,5]。在Python中计算两个长度相同的列表的欧氏距离,可以使用以下代码:
1 | #导入numpy库 |
3. 识别人脸
两个向量的欧氏距离越小,说明两个向量越接近。将这个结论放在人脸识别中,可以得出以下结论:
两张人脸特征向量的欧氏距离越小,说明两个人越相似。当欧氏距离小于某一个值时,则可以认为他们是同一个人。
基于这个结论,我们可以实现人脸识别。
(1)准备数据
将事先准备的人脸图片作为本次识别的数据,并把图片分成两个部分。第一个部分为已知的图片,另一部分为待识别的图片。
在本关实训中,已知图片放在step1/image/known_image中,包含“佟大为”以及长得很像的“夏雨”和“张一山”。
在待识别图片中放在step1/image/test_image中,包含“佟大为”、“夏雨”以及“张一山”,以及未在已知图片中出现的”李亚鹏“。
理想情况下,人脸识别算法应该做到:如果待识别图片中的人出现在了已知图片中,那么应该正确地输出姓名,否则,就输出Unknow。
(2)计算所有已知图片中人脸的特征向量
因为需要获取所有已知图片中的特征向量,首先得获取到图片。在这里我们借助glob模块下的glob()来获取图片。
1 | # 函数声明 |
glob()会返回匹配的文件列表,这样我们就可以获取到在known_image_path下所有以jpg结尾的的图片,代码如下:
1 | import glob |
然后可以来计算所有已知图片中人脸的特征向量,代码如下所示:
1 | known_image_path = "step1/image/known_image" |
(3)识别人脸
当欧氏距离小于某个阈值时,则可以认为他们是同一个人。那这个阈值应该设定为多少呢?
在Dlib中,对于在LFW人脸数据集,当阈值设置为0.6时,的识别精度能达到99.38%\。但是,当阈值设置为0.6时,对于小孩和亚洲人的识别率不是很高。而本次我们要识别的几张图片都是亚洲人,所以将阈值适当地降低,在这里我们设置为0.4。
所以,计算待识别的图片特征向量与已知图片特征向量的欧氏距离,如果欧氏距离小于阈值,则认为是同一张图片。具体代码片段如下:
1 | tolerance = 0.4 |
人脸识别完整代码:
1 | import os |
二、绘制人脸识别结果
添加人脸矩形框
绘制人脸区域
1
cv2.rectangle(img,(d.left(), d.top()),(d.right(), d.bottom()),(0,0,255),2)
在人脸矩形框旁添加文字
接下来,在人脸矩形框旁添加文字。首先,在
OpenCV中提供了cv2.putText()函数用于给图片添加文字。1
2# 函数声明
cv2.putText(图片对象, 文字内容, 坐标, 字体, 字体倍数, 字体颜色, 字体厚度)如果想在
img中的(3,3)处添加文字内容Hello,且要求文字内容的字体为cv2.FONT_HERSHEY_PLAIN,字体倍数为0.5倍,字体颜色为红色(0,0,255),字体厚度为1。那么对应的代码就是:1
cv2.putText(img,"Hello",(3,3),cv2.FONT_HERSHEY_PLAIN,0.5,(0,0,255),1)
在图片上添加文字
然后,为了让名字看得清楚,我们将文字的坐标设置为:
(d.left() + 6, d.bottom() - 6)。所以,添加文字的代码如下:1
2font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(img, current_name, (d.left() + 6, d.bottom() - 6), font, 0.5, (255, 255, 255), 1)
完整代码示例:
1 | import os |

